본 글은 ZIO에 대한 기본적인 이해를 전제로 하고 있으니, ZIO에 대한 간략한 소개는 포트원 V2 이야기 - Scala와 ZIO로 안정적인 결제 시스템 만들기를 참고해주세요.
사전 배경: CQRS 패턴의 도입
포트원 V2 모듈은 CQRS 패턴을 활용하고 있습니다. 앞선 글에서 소개드렸듯이 포트원 V2는 이벤트 소싱이라는 디자인 패턴을 도입했는데, 이벤트 소싱을 하게 되면 데이터가 훨씬 상세하게 남는다는 장점이 있지만 상태가 아닌 개별 이벤트들이 DB에 저장되므로 다양한 필터를 통한 조회 요구사항에는 적절하지 않습니다. 하지만 포트원 콘솔에는 다양한 필터 조건을 걸고, 정렬을 하며, 심지어는 full-text search 까지 지원해야 하는 등의 고도화된 조회 요구사항이 존재합니다. 이러한 요구사항을 만족하기 위해 Write DB와 Read DB를 분리해서 사용하기로 결정했는데, 이러한 데이터 접근 패턴을 CQRS 패턴이라고 부릅니다.
문제 상황
CQRS 패턴을 구현하기 위해서는 Write DB에서 발생한 변경 사항을 Read DB에도 반영시켜주는 파이프라인이 필요한데, Read DB를 통해 포트원에서 발생한 모든 결제건을 누락없이 볼 수 있어야 하므로 이 파이프라인의 신뢰성을 높이는 것은 매우 중요합니다. 포트원 V2의 코어 모듈은 이 파이프라인의 시작점이라고 할 수 있는데, Write DB에 발생한 변경사항을 주기적으로 캐치하여 Kafka로 publish를 해주는 background job이 존재합니다.
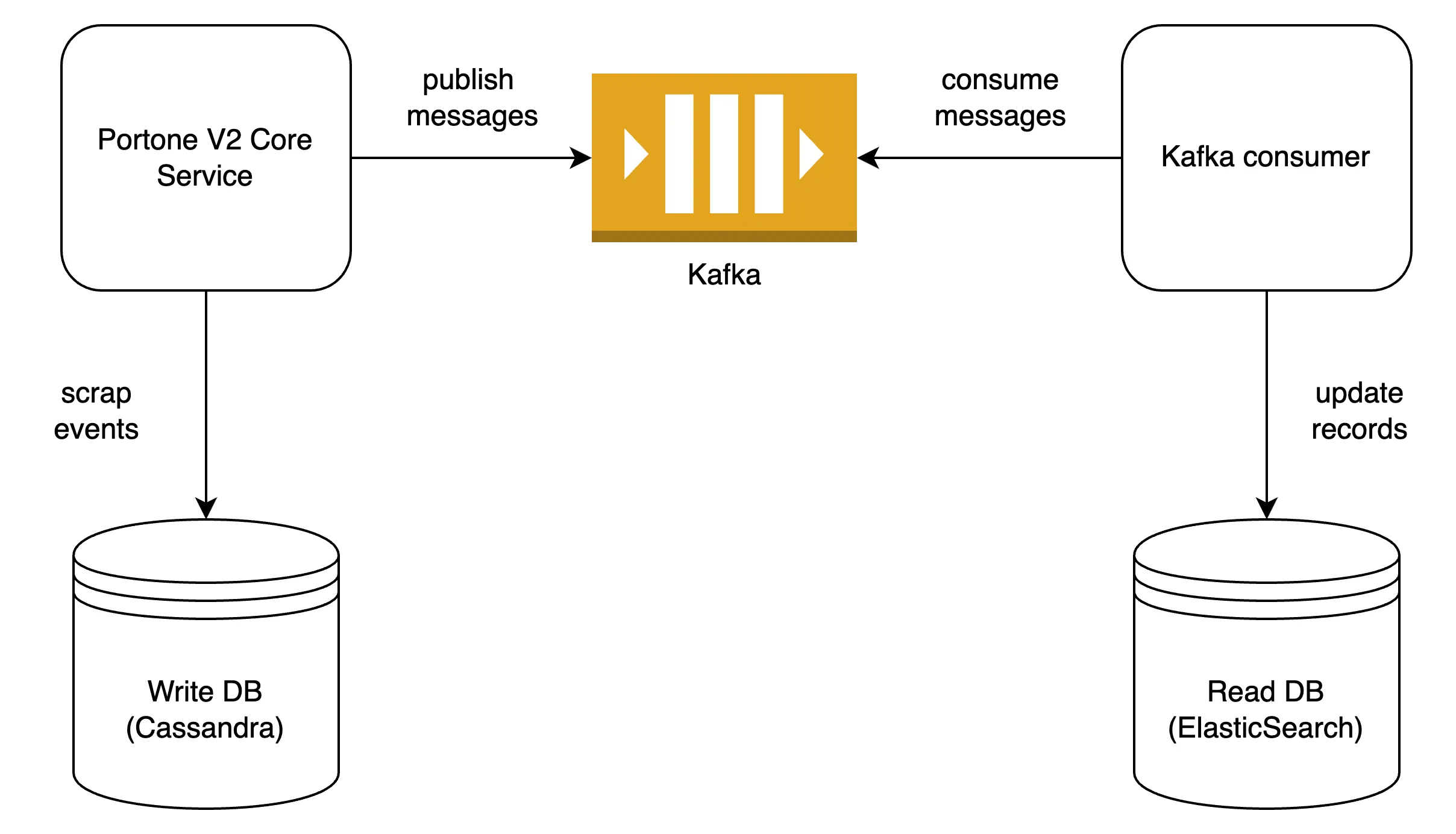
이러한 job은 recursive하게 자기 자신을 주기적으로 호출하는 방식으로 작성되어 있었는데, 대략 아래와 같은 코드로 단순하게 표현할 수 있을 것입니다.
private def scrapAndPublish: UIO[Nothing] =
for {
events <- getEvents
_ <- publish(events)
nothing <- scrapAndPublish.delay(1.second)
} yield nothing해당 코드를 배포하고 난 직후엔 아무 문제 없이 의도한대로 잘 동작하였으나, 코드를 배포한 지 며칠이 지나자 OOM이 발생해 어플리케이션이 강제로 재시작되었고 다시 며칠동안은 문제가 없다가 OOM이 발생하기를 반복했습니다. 아래의 두 사진 중 위의 것은 문제가 된 인스턴스의 JVM old generation size 추이를 나타낸 그래프이고, 아래의 사진은 같은 메트릭에 대해 문제가 없는 인스턴스의 일반적인 그래프입니다.
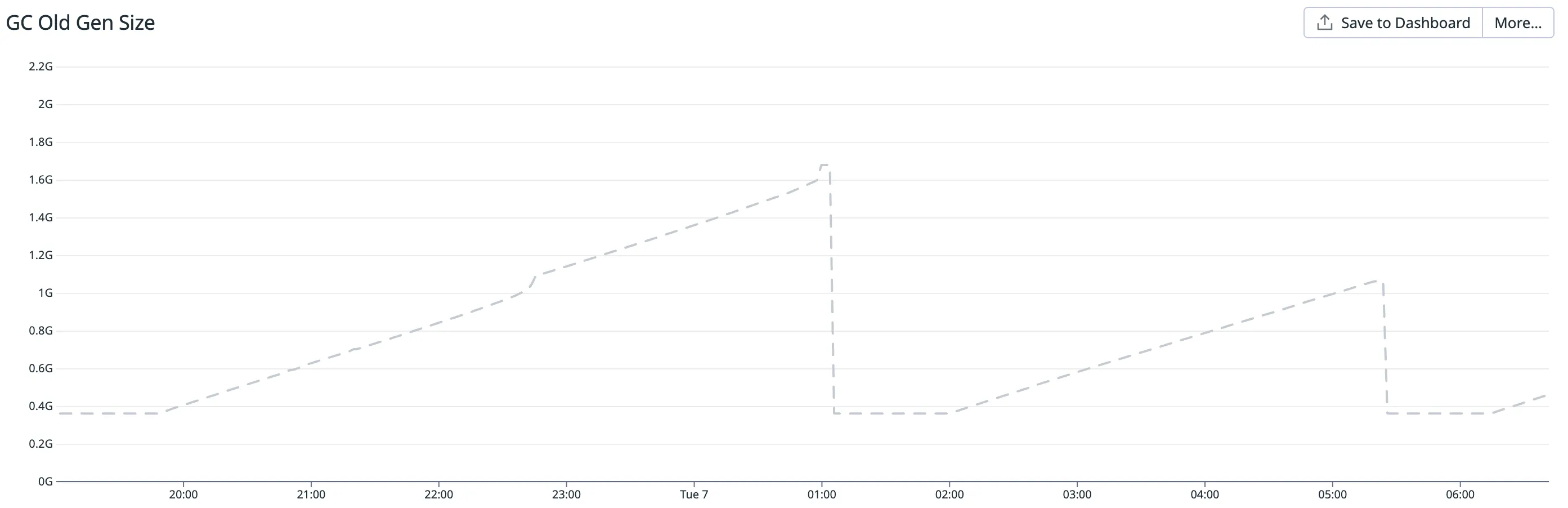
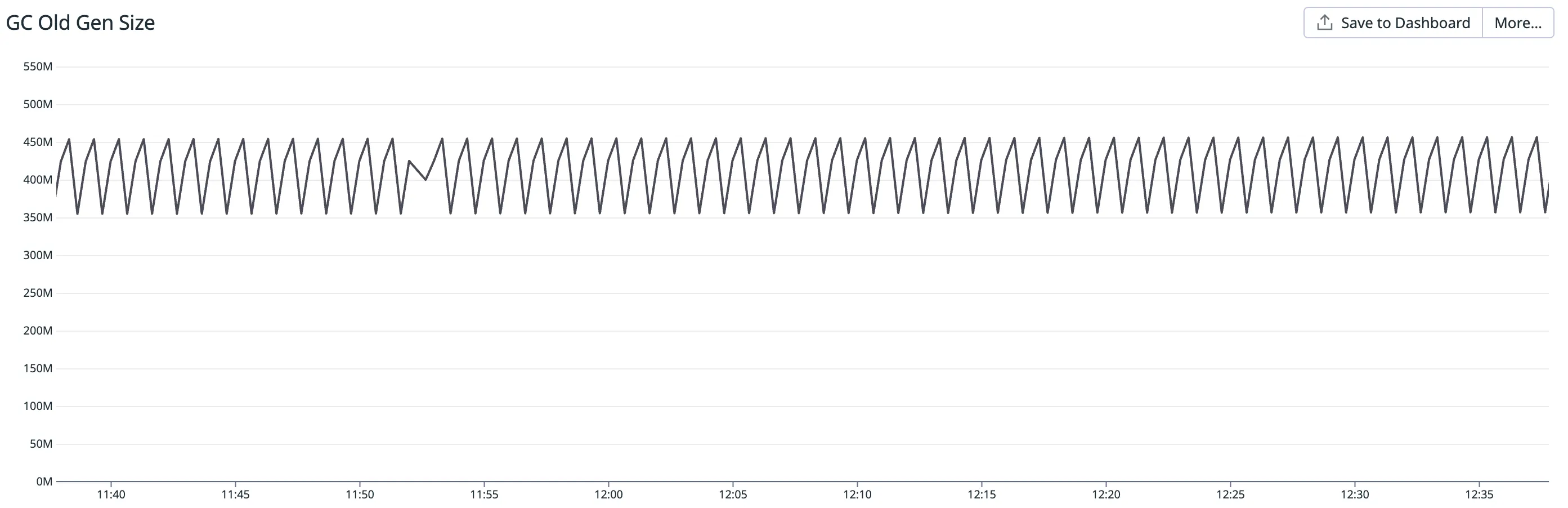
그래프를 통해 계속적인 재귀 호출로 인해 메모리가 정리되지 않고 계속해서 쌓이고 있음을 짐작할 수 있었고, 이 이슈를 해결하기 위해 몇 가지 실험과 ZIO의 코드 분석을 진행했습니다.
무한 재귀인데 OOM이 나는 이유
그런데 무언가 이상했습니다. 상황을 확인하고 가장 먼저 든 생각은 “무한 재귀 호출로 인해 문제가
생긴거라면 OutOfMemoryError가 아니라 StackOverflowError가 발생해야 하는 것 아닌가?”하는
것이었습니다. 일반적으로 함수의 호출은 스택이라는 메모리 공간에 스택 프레임을 생성하기 때문에 함수
호출의 깊이가 매우 깊어지면 스택에 남은 공간이 없어질 것이기 때문이죠. 예를 들어 아래와 같은
Option을 이용한 무한 재귀 호출 코드는 StackOverflowError를 발생시킬 것입니다.
def optionInfRec(n: Int): Option[Nothing] =
Some(n).flatMap(_ => optionInfRec(n + 1))
optionInfRec(0)
--- 실행결과 ---
java.lang.StackOverflowError
at scala.Option.flatMap(Option.scala:283)
at io.portone.tx.InfRecSpec$.optionInfRec$1(InfRecSpec.scala:11)
at io.portone.tx.InfRecSpec$.$anonfun$spec$2(InfRecSpec.scala:12)
at io.portone.tx.InfRecSpec$.$anonfun$spec$2$adapted(InfRecSpec.scala:11)
at scala.Option.flatMap(Option.scala:283)
at io.portone.tx.InfRecSpec$.optionInfRec$1(InfRecSpec.scala:11)
at io.portone.tx.InfRecSpec$.$anonfun$spec$2(InfRecSpec.scala:12)
at io.portone.tx.InfRecSpec$.$anonfun$spec$2$adapted(InfRecSpec.scala:11)하지만 ZIO를 이용한 무한 재귀 호출 코드는 StackOverflowError를 발생시키지 않습니다.
def zioInfRec(n: Int): UIO[Nothing] =
ZIO.succeed(n).flatMap(_ => zioInfRec(n + 1))
unsafeRun(zioInfRec(0))ZIO의 Lazy Evaluation
ZIO의 경우에만 StackOverflowError 가 발생하지 않는 이유는 우선 ZIO는 flatMap의 인자로 전달 받은 함수를 즉시 평가하지 않기 때문입니다.
지난 글에서 ZIO는 동작을 기술하는 data type일 뿐이라고 소개했던 것을 기억하시나요?
ZIO에서 제공하는 flatMap이라는 함수에서는 파라미터로 받은 k 함수를 평가하지 않고 OnSuccess라는 data type에 그대로 넣어주고 있습니다.
def flatMap[R1 <: R, E1 >: E, B](k: A => ZIO[R1, E1, B])(implicit trace: Trace): ZIO[R1, E1, B] =
ZIO.OnSuccess(trace, self, k) // OnSuccess는 ZIO의 subtype입니다.반면 Option의 flatMap 구현을 보면 파라미터로 받은 f 함수를 즉시 평가하고 있습니다.
@inline final def flatMap[B](f: A => Option[B]): Option[B] =
if (isEmpty) None else f(this.get)다시 말해 위의 무한 재귀 호출 코드에서 재귀 호출이 일어나는 부분은 lambda 함수로 감싸져 있는데, ZIO는 이 함수를 즉시 평가하지 않기 때문에 이 코드는 실제로는 재귀 호출을 하지 않는 코드가 되는 것이죠! 이를 확인하기 위해 우리가 만든 ZIO를 한번 콘솔에 출력해보겠습니다.
OnSuccess(
io.portone.tx.InfRecSpec.zioInfRec(InfRecSpec.scala:10),
Sync(
io.portone.tx.InfRecSpec.zioInfRec(InfRecSpec.scala:10),
io.portone.tx.InfRecSpec$$$Lambda$1000/0x00000008012be5e8@398d44c6
),
io.portone.tx.InfRecSpec$$$Lambda$1001/0x00000008012be8a8@781006f6
)실제로 OnSuccess가 계속해서 nested된 형태가 아니라, lambda 함수의 reference만 들어있는 것을 확인할 수 있습니다.
ZIO가 실제로 실행되는 원리
여기까지 확인을 했다면, “이건 단순히 평가 시점을 뒤로 미룬 것 뿐이고, 나중에 lambda가 실제로
평가될 때는 결국 문제가 발생하는거 아닌가?” 하는 생각이 들 수 있습니다. 이 부분에 대한 궁금증을
해소하기 위해서는 우선 단순한 데이터 타입에 불과한 ZIO가 어떻게 실제로 실행되는지에 대해 이해해야
하는데요, 이 때 알아야 하는 개념이 Fiber와 FiberRuntime입니다.
Fiber와 FiberRuntime
ZIO는 Fiber라는 객체 위에서 실행되고 그 실행 환경을 구체적으로 정의한 구현체를 FiberRuntime이라고 부릅니다.
// 실행하고자 하는 zio 객체를 이용해 Fiber를 만듭니다.
val fiber = makeFiber(zio)
// Fiber.start 함수를 호출하면 zio가 실제로 평가됩니다.
fiber.start(zio)FiberRuntime 에는 실제로 ZIO를 한 단계씩 실행해나가는 runLoop 라는 함수가 존재하는데, 이 함수는
ZIO를 바깥에서부터 하나씩 처리하고 다음 평가할 ZIO를 만들어 이어서 처리하는 식으로 구현되어
있습니다. 위에서 소개한 OnSuccess 객체를 처리하는 로직은 어떻게 작성되어 있을까요? OnSuccess 는
순차 실행을 추상화한 데이터 타입이며, 그렇기 때문에 가장 기본적이고도 가장 강력한 Effect 조합기라고
할 수 있습니다. 이를 처리하는 코드를 직접 살펴보겠습니다. (편의를 위해 코드를 단순화했으며, 실제
ZIO의 코드와는 상이한 부분이 있을 수 있습니다.)
private def runLoop(effect: ZIO[Any, Any, Any], currentDepth: Int): AnyRef = {
...
effect match {
case onSuccess: OnSuccess[_, _, _, _] =>
val first = onSuccess.first
val andThen = onSuccess.successK
// 첫번째 effect를 runLoop 함수를 재귀호출하여 평가하고,
// andThen 함수에 이 결과를 넣어 이어서 평가할 ZIO 객체를 만듭니다.
val continuation = andThen(runLoop(first, currentDepth + 1))
...
case ... // handling other cases
}
}Stack Safety를 위한 Trampoline
위 코드에서 하는 일은 첫번째 ZIO를 runLoop 함수를 재귀호출하여 먼저 평가하고, 그 결과를 가지고
andThen 함수를 호출해 이어서 평가할 ZIO 객체를 만드는 것입니다. 어쨌거나 runLoop 함수를 재귀
호출하기 때문에 원래 가졌던 궁금증처럼 여기서도 결국 StackOverflowError가 발생할 가능성이
있어보입니다. 하지만 그럼에도 실제로는 StackOverflowError가 발생하지 않았던 이유는 무엇일까요? 그
이유는 함수 호출의 깊이가 특정 임계값에 도달하면 즉시 스택을 비우고 연산을 한번 중지했다가 다시
시작하는 로직이 존재하기 때문입니다. runLoop 함수의 파라미터로 currentDepth 가 존재하는 것이
보이시나요? 재귀 호출을 할 때마다 이 값을 하나씩 늘려 호출을 하고, 함수의 첫 시작 부분에는 이 값이
임계치에 도달했는지를 확인하는 로직이 존재합니다.
if (currentDepth >= FiberRuntime.MaxDepthBeforeTrampoline) {
...
throw Trampoline(effect, false)
}여기서 발생한 Trampoline 이라는 에러를 catch하는 로직은 아래와 같습니다.
...
catch {
case trampoline: Trampoline =>
tell(FiberMessage.Resume(trampoline.effect))
}이렇게 연산을 실제로 이어나가는 대신, “연산을 재개해라”라는 명령을 추상화한 객체를 만듦으로써
명시적으로 스택을 비워 stack safety를 달성할 수 있습니다. Exception의 이름이 Trampoline 이라는
것이 조금 특이한데, 사실 Trampoline이란 이렇게 함수의 stack safety를 보장하기 위해 stack 대신
heap을 사용해 연산을 이어나가는 일반화된 패턴을 의미하는 용어입니다. Trampoline은 stack safety를
보장할 수 있는 우아한 함수형 기법이지만, heap을 이용하기 때문에 메모리 동적 할당에 따른 오버헤드를
감수해야 하고 메모리에 random access를 해야 하기 때문에 stack을 일반적으로 이용하는 것보다
locality가 떨어져 cache 효율성이 낮아질 수 있습니다.
이제 진짜 원인 파악을 해보자
여기까지 이해를 했다면, 원래의 코드에서 왜 문제가 생겼는지를 쉽게 이해할 수 있습니다. 사실 runLoop
함수에서 하는 일이 한 가지 더 있는데, 함수 호출의 깊이가 깊어져 trampoline이 발생하게 되면 현재
effect를 나중에 평가하기 위해 stack에 쌓아두는 것입니다. 이 작업을 추가한 runLoop 코드는 다음과
같습니다.
private def runLoop(effect: ZIO[Any, Any, Any], currentDepth: Int): AnyRef = {
...
effect match {
case onSuccess: OnSuccess[_, _, _, _] =>
val first = onSuccess.first
val andThen = onSuccess.successK
// 첫번째 effect를 runLoop 함수를 재귀호출하여 평가하고,
// andThen 함수에 이 결과를 넣어 이어서 평가할 ZIO 객체를 만듭니다.
try {
val continuation = andThen(runLoop(first, currentDepth + 1))
} catch {
case trampoline: Trampoline =>
// trampoline이 발생하면 나중에 effect를 다시 실행하기 위해 stack에 저장합니다.
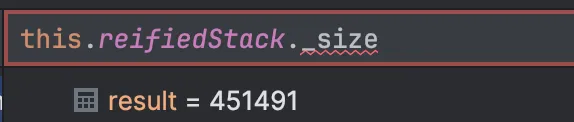
self.reifiedStack += effect
throw trampoline
}
...
case ... // handling other cases
}
}우리의 코드는 trampoline이 무한히 발생해 stack에도 effect들이 무한히 쌓이게 되므로 OOM이 발생하는 것이었습니다!
해결 방법
원인을 파악하기까지 꽤나 힘들었지만, 해결 방법은 단순합니다. 그것은 Scala의 for-comprehension을
사용하지 않는 것인데요, for-comprehension으로 만들어진 코드는 우리가 정확히 원하는 코드와는 약간의
차이가 있습니다. 윗부분에서 소개한 zioInfRec 함수를 for-comprehension 스타일로 바꾼다면 아래와
같이 작성할 수 있을 것입니다.
def withForComprehension(n: Int): UIO[Nothing] =
for {
_ <- ZIO.succeed(n)
nothing <- withForComprehension(n + 1)
} yield nothing그리고 이 코드는 아래의 코드와 동치입니다.
def withForComprehension2(n: Int): UIO[Nothing] =
ZIO
.succeed(n)
.flatMap(_ => withForComprehension2(n + 1).map(nothing => nothing))가장 마지막 부분에 .map(nothing => nothing) 이 붙는 것이 보이시나요? 이 부분은 사실 없어도 되는
코드이지만, for-comprehension의 변환 규칙에 의해 어쩔 수 없이 붙게 되는 코드입니다. 의미적으로는
사실상 같은 일을 하는 코드이지만, 만들어지는 ZIO의 구성 자체는 분명한 차이점을 가지고 있으며 이를
FiberRuntime 위에서 실행할 때도 동작 방식에서 큰 차이를 갖게 됩니다.
for-comprehension 사용 유무에 따른 구조적 차이
마지막 부분에 .map(nothing => nothing) 이 추가된 경우와 그렇지 않은 경우를 각각 콘솔에
출력해보았습니다. (이해를 돕기 위해 단순화하여 편집한 출력입니다. 크게 신경쓰지 않아도 되는
파라미터는 생략하였으며, lambda 함수의 reference들은 단순하게 lambda 라고만 표기하였습니다.)
// 1. map(nothing => nothing)이 추가되지 않은 경우
OnSuccess(
Sync(lambda),
lambda
)
// 2. map(nothing => nothing)이 추가된 경우
OnSuccess(
OnSuccess(
Sync(lambda),
lambda
),
lambda
)두 ZIO의 구조적인 차이가 확인되시나요?
1번의 경우 OnSuccess 가 한 겹만 존재하는데 반해, 2번의 경우는 OnSuccess 안에 다시 OnSuccess 가 존재하는 구조입니다.
이렇게 OnSuccess 가 한 겹 더 생기는 이유는 map 함수는 단순히 flatMap 함수 호출을 wrapping하는 식으로 구현되어 있기 때문입니다.
def map[B](f: A => B): ZIO[R, E, B] = flatMap(a => ZIO.succeed(f(a)))1번의 경우 OnSuccess 케이스를 FiberRuntime 에서 처리할 때 재귀호출 하는 runLoop 의 파라미터로
항상 Sync 를 넣어주기 때문에 해당 재귀 호출은 중첩된 재귀 호출을 하지 않고 곧바로 리턴될 것입니다.
반면 2번의 경우 OnSuccess 가 두 번 겹쳐 있으므로, runLoop 재귀 호출의 파라미터로 OnSuccess 를
넣어주게 되고 이는 중첩된 runLoop 재귀 호출을 유발합니다. 중첩된 재귀 호출은 Trampoline을 일으킬
것이고, 이 때 stack에 있던 중첩된 effect들이 heap (reifiedStack)으로 옮겨가면서 메모리를 차지하게
됩니다.
문제 해결
다시 맨 첫부분의 scrapAndPublish 예시로 돌아가서, 해당 함수를 아래와 같이 for-comprehension을
사용하지 않도록 바꿈으로써 문제를 해결할 수 있습니다.
private def scrapAndPublish: UIO[Nothing] =
getEvents
.flatMap(events => publish(events))
.flatMap(_ => scrapAndPublish.delay(1.second))또한
better-monadic-for이라는
Scala compile plugin을 적용하면 for-comprehension을 없애지 않고도 문제를 해결할 수 있습니다! 이
글에서 설명하는 경우와 같이 마지막 부분에 불필요한 map 함수를 해당 플러그인이 제거해줍니다.
마무리
이번 글에서는 ZIO를 사용하면서 겪었던 OOM 이슈에 대해 그 원인과 해결 방법을 알아보았습니다. 원인을 분석해보면서 ZIO의 FiberRuntime 개념, Trampoline 패턴, for-comprehension의 작동 방식 등 흥미로운 여러 주제들에 대해서도 함께 공부할 수 있는 시간이었던 것 같습니다.
우리는 기술을 통해 온라인 결제 시장을 혁신하고자 하는 팀입니다. 이와 같은 기술적인 고민을 함께 하며 포트원의 미션에 동참하고 싶으신 분들은 언제든지 포트원의 문을 두드려주시면 감사하겠습니다!