안녕하세요. 포트원 V2 이야기로 다시 돌아온 포트원 엔지니어 Kai입니다. 포트원 V2 시스템을 구성하고 있는 핵심 기술들 중 이번에 소개해 드릴 것은 Event Sourcing이라는 기술입니다. Event Sourcing이 무엇인지, 포트원이 결제 시스템을 구축하는 데에 왜 이 기술을 도입하기로 결정했는지, 도입을 결정하면서 함께 신경 쓴 것들은 무엇인지, 직접 기술을 적용하면서 느낀 챌린지는 무엇인지 등에 대해 정리해 보도록 하겠습니다. (참고로 Event Sourcing에 관한 글은 기본편과 심화편으로 나누어 업로드될 예정입니다!)
Event Sourcing이란?
Event Sourcing이란 DB에 데이터를 저장하는 방식에 관한 기술입니다. 일반적으로 백엔드 어플리케이션을 만들 때, DB에는 보통 State(상태)를 저장하곤 합니다. 이러한 방식은 직관적이어서 이해하기 쉽다는 장점이 있지만, 항상 엔티티의 최종 상태만을 담고 있기 때문에 변경된 기록을 정확하게 추적할 수 없고, 한 데이터에 대해 검색 및 변경 요청이 빈번하게 발생하기 때문에 동시성으로 인한 문제를 피하려 많은 고민을 해야 합니다.
반면 Event Sourcing 방식에서는 종 상태만을 저장하는 것이 아니라, 엔티티의 상태를 변경하기 위해 발생하는 하나하나의 사건(Event)들을 모두 DB에 저장합니다. 때문에 특정 엔티티에 대한 변경 내역을 모두 추적할 수 있으며, 이벤트는 한 번 발생한 이후 수정되지 않기 때문에 Update나 Delete 없이 항상 Insert 작업만 일어납니다.
결제와 Event Sourcing
포트원은 이러한 Event Sourcing이라는 기술을 왜 도입하기로 결정했을까요? 아시다시피 포트원은 오랜 시간 동안 PG 통합 결제 모듈을 제공해왔고 그동안 많은 시행착오와 노하우를 쌓아왔습니다. Event Sourcing을 사용하기로 결정하는 데에는 기존의 시스템을 운영하면서 가지고 있던 아쉬움들이 큰 영향을 주었는데요, 크게 두 가지 정도를 소개 드릴 수 있을 것 같습니다.
1. 정확한 내역 파악의 필요성
기존 시스템을 운영하면서 느꼈던 가장 큰 pain point는 결제건에 대한 변경 내역을 정확히 알 수 없다는 것이었는데요, 아래와 같이 구체적인 변경 내역을 물어오는 문의들이 여러 고객사로부터 자주 있었습니다.
- 어떤 결제건에 부분 환불 요청을 총 몇 번 / 각각 언제 했는지
- 어떤 결제건의 특정 타입의 웹훅이 몇 번 재시도 되었는지
- 어떤 결제건의 PG사 승인 응답 전문이 무엇인지
기존에는 이러한 문의가 들어오면 로그를 확인해 보곤 하는데, 로그는 영원히 검색 엔진에 올려둘 수가 없기 때문에 시간이 오래 지난 변경 내역은 확인하기가 힘듭니다. 따라서 완벽한 답변을 드릴 수 없었던 경우도 종종 있었는데, Event Sourcing을 도입하게 되면 엔티티에 가해진 모든 이벤트가 DB에 저장되기 때문에 이렇게 맥락 파악을 요청하는 문의에 완벽하게 대응할 수 있을 것이라고 생각했습니다. 또한 포트원은 데이터를 기반으로 여러 가지 인사이트를 제공하고 운영 효율화를 도와줄 수 있는 B2B SaaS 기업으로의 도약을 계획하고 있었는데, 이러한 상황에서 Event Sourcing 방식으로 쌓인 풍부한 raw data는 앞으로 포트원의 발전을 뒷받침할 든든한 뿌리가 될 것이라고 생각했습니다. 종합해 보면, 무엇보다 결제라는 행위는 돈을 주고받는 것이기 때문에 결제 서비스를 제공하는 입장에서 데이터를 최대한 정확하게 보관하는 것이 매우 중요하다고 생각하여 Event Sourcing이 매력적인 선택지로 다가왔던 것 같습니다.
2. 자유로운 스키마 발전의 필요성
기존 시스템이 갖고 있던 또 하나의 pain point는 DB Schema에 관한 것인데요,
아시다시피 포트원은 국내외의 여러 PG사 결제 모듈을 하나의 인터페이스, 하나의 플로우로 통합해 주는 PG 통합 연동 모듈을 제공하고 있습니다.
때문에 어떤 PG사를 포트원에서 추가적으로 지원하기 위해 작업을 할 땐 해당 PG사에서 지원하는 파라미터 목록을 확인한 후,
포트원에서 이미 정의한 파라미터로 맵핑할 수 있는지를 검사합니다. 만약 맵핑할만한 파라미터가 마땅히 존재하지 않는다면 포트원에서는 새로이 인터페이스에 파라미터를 추가하고 내부 디비에도 해당 데이터를 저장할 수 있도록 스키마를 발전시켜야 합니다.
포트원의 기존 시스템은 MySQL을 사용하고 있었고, DB 스키마의 지원을 받아 데이터를 정형화하여 관리하고 있었습니다.
때문에 스키마에 필드를 추가하고 싶을 땐 ALTER TABLE ADD COLUMN 과 같은 DDL을 실행해야 하는데요,
기술이 많이 발전했다고 해도 Online DDL 실행은 여전히 개발자들에게 어렵고 부담스러운 작업입니다.
처리해야 할 데이터의 양이 많다면 DDL 실행이 완료되기까지 시간이 굉장히 오래 걸릴 수 있으며,
그동안 DB Server의 자원을 많이 점유해 실 서비스에 영향을 줄 수도 있습니다.
반면 Event Sourcing을 하게 되면 DB Schema에 의존하지 않고 자체적인 Event 포맷 정의 및 직렬화/역직렬화 전략을 구성하게 되기 때문에 이러한 문제로부터 완전히 자유로울 수 있습니다. 사실 스키마를 자유롭게 구성할 수 있다는 점이 백엔드 개발에서 큰 장점이 되는 경우가 많지는 않은데, 포트원은 여러 PG사의 인터페이스를 통합하는 특성을 갖고 있기 때문에 이 점을 큰 장점으로 생각하게 되었습니다.
Event Sourcing과 잘 어울리는 DB 고르기
1. Event Sourcing의 DB 접근 특징
Event Sourcing은 한마디로 DB에 최종 상태만을 저장하는 것이 아니라 개별 이벤트를 모두 저장하는 기술인데요, 이 때문에 어플리케이션에서 DB에 접근하는 패턴이나 DB를 다루는 방식이 어느 정도의 특징을 띠게 됩니다. 이를 대략적으로 정리해보면 아래와 같습니다.
- Update/Delete 없이 항상 Insert와 Select만 발생한다.
- 이벤트의 형태는 매우 다양하므로, DB Schema에 의존하지 않는 자체적인 Event 직렬화 전략이 필요하다.
- 쿼리가 다양하지 않고 단일하다. (Insert 쿼리 한 개, Select 쿼리 한 개)
- 상태가 아닌 개별 이벤트를 저장하므로 굉장히 많은 양의 데이터가 쌓인다.
2. 특징에 어울리는 DB 고르기
그리고 이러한 특징들과 잘 어울리는 DB로는 어떤 것이 있을까요? 이 특징들을 잘 서포트하는 DB를 고르기 위해서는 DB가 갖추어야 하는 기능과 갖추지 않아도 되는 기능을 정리해 볼 필요가 있습니다.
- Insert와 Select query만 발생하며 쿼리가 복잡하지 않음 → Transaction 지원이 그다지 필요하지 않음
- DB Schema를 활용해 데이터를 정형화할 필요가 없음 → Schemaless DB를 사용해도 무방
- 데이터가 매우 많이 쌓임 → Scale out이 자유로운 DB를 사용해야 함
위와 같은 요구사항을 잘 만족하는 DB는 무엇일까요? 많은 선택지가 있을 수 있겠지만 일반적으로 NoSQL DB를 우선 떠올릴 수 있습니다. 포트원에서도 Cassandra라는 NoSQL DB를 Event Sourcing을 위한 DB로 사용하고 있는데요, Cassandra는 특히 peer-to-peer architecture를 갖는 Dynamo Style의 DB로 이론상 무제한에 가까운 Scalability를 제공하기 때문에 Event Sourcing에서 사용하기에 적합하다고 판단했습니다.
3. 이외 고려할 것들
물론 위에 적은 내용들만을 고려해서 DB를 선택할 수 있는 것은 아닙니다. 무엇보다 어플리케이션에 존재하는 모든 영속 엔티티를 Event Sourcing 방식으로 관리할 필요는 없기 때문에 보다 일반적인 용례를 커버할 수도 있어야 하는데, 이 점을 생각한다면 SQL 인터페이스를 제공하며 Transaction 지원도 되고 수평 확장도 용이한 Google Spanner나 CockroachDB 등을 사용하는 것을 고려해 볼 수도 있습니다. 이러한 DB를 사용하지 않은 이유를 정리해 보면 크게 아래와 같습니다.
1) 검증되지 않은 DB
Google Spanner나 CochroachDB와 같이 NoSQL과 SQL의 장점을 융합하려는 시도는 비교적 최근에 이루어지고 있는 것이고, 해당 DB에 대해 아주 잘 알고 있는 개발자가 사내에 존재하는 것이 아니라면 충분히 검증된 다른 DB를 사용하는 것이 낫다고 판단했습니다.
2) MSA 환경
저희는 Microservice Architecture를 구성해두었기 때문에 Event Sourcing이 필요한 Bounded Context가 꽤 명확한 편이었습니다. 따라서 해당 Context 내에서는 Event Sourcing으로 커버하기 힘든 유스케이스가 거의 없다는 점도 의사결정의 주된 고려 사항이었습니다.
3) AuroraDB 도입을 위한 환경이 이미 마련되어 있음
저희 아키텍처의 다른 마이크로 서비스들은 모두 AuroraDB를 활발하게 사용하고 있었기 때문에 NoSQL로 커버할 수 없는 용례가 나타나더라도 언제든 AuroraDB를 쉽게 도입할 수 있었습니다.
결과적으로 저희는 대부분의 상황에서 NoSQL을 이용해 Event Sourcing을 하고 있고, 내부적으로 존재하는 사소한 유스케이스에 대해서는 AuroraDB를 사용하여 서비스를 운영하고 있습니다.
Event Sourcing 구현 살펴보기
Event Sourcing의 특징과 의사결정 배경을 살펴보았으니, 이제 실제 구현에 대해서도 간단하게 살펴보겠습니다. Event Sourcing은 생소한 기술이긴 하지만 핵심 아이디어 자체는 매우 간단합니다. 로직을 수행하는 과정에서 일어난 사건들을 이벤트로 저장하고, 이 이벤트들을 이용해 외부로 노출될 상태를 만들어내는 것입니다. 이러한 아이디어를 구현하는 데에 필요한 핵심적인 함수 두 가지가 있습니다.
commandHandler: (Command, State) => ResponseeventHandler: (State, Seq[Event]) => State
이 두 함수에 대해 알아보기 이전에 Command, Event, State가 무엇인지를 먼저 설명하겠습니다.
Command: 특정 로직의 수행을 지시하는 명령입니다. HTTP에 비유하자면 Request의 역할을 한다고 이해하시면 좋을 것 같습니다.Event:Command를 받아 로직을 수행하는 과정에서 발생하는 사건들을 표현하는 객체입니다. 이Event들은 DB에 저장되어 Single Source Of Truth의 역할을 합니다.State: 일련의Event들이 모여 결과적으로 만들어지는 상태를 뜻합니다. 일반적으로 백엔드 애플리케이션에서 흔히 다루는 도메인 엔티티라고 생각하시면 됩니다.
기본적인 개념에 대해 알았으니, 이제 commandHandler 와 eventHandler 가 무엇인지는 쉽게 이해할 수 있을 것 같습니다.
commandHandler: 현재 상태(State)에서 명령(Command)를 받아 도메인 로직을 수행하고, 응답을 리턴하는 함수입니다. 로직을 수행하는 과정에서 이벤트를 쌓을 때마다eventHandler를 호출합니다.eventHandler: 현재 상태(State)에서 어떤 이벤트(Event)가 새로 쌓이게 되면 어떤 새로운 상태로 전이할지를 정의하는 함수입니다.
그다지 어렵지 않죠? commandHandler는 일반적인 어플리케이션에서 작성하는 도메인 로직과 유사하지만 DB에 상태를 직접 업데이트하는 것이 아니라 이벤트를 쌓을 뿐이고,
새롭게 쌓인 이벤트를 가지고 최신 상태를 만들어내는 코드가 eventHandler에 정의되는 것입니다. commandHandler의 예시를 하나 들어보겠습니다. 수기 결제 요청을 받아 수행하는 commandHandler입니다.
// commandHandler: 설명을 위해 단순화한 예시 코드입니다.
for {
// 1. 수기결제를 시작한다는 내용의 이벤트 저장
_ <- persist(Event.CommandReceived(id, form, store, customer))
// 2. 사용자가 넘긴 channel key를 이용해 channel 얻어오기
channel <- channelService
.fetchChannel(store.id, form.channelKey)
.flatMapError(e => fail(Event.FetchingChannelFailed(form.channelKey, e)))
// 3. 채널 정보 요청 결과를 이벤트로 저장
_ <- persist(Event.FetchingChannelSucceeded(channel))
// 4. 채널을 이용해 PG사에 수기결제 요청하기
result <- txGatewayService
.payInstantly(base, channel, paymentMethodForm)
.flatMapError(e => fail(base, channel, Event.TgsFailed(e)))
// 5. 수기 결제 요청 결과를 이벤트로 저장
_ <- persist(Event.TgsSucceeded(result))
...
} yield Response.Succeeded(result)위 코드에서 persist함수를 호출할 때마다 DB에 이벤트가 쌓이게 되고, eventHandler를 거쳐 상태가 업데이트되는데요,
persist함수를 어떻게 주입하고 있는지도 확인해 보겠습니다.
eventHandler 역할을 하는 handleEvent 함수에서 상태가 어떻게 전이되는지 확인할 수 있습니다.
val persist = new Persist[E] {
def apply(event: E): UIO[Unit] =
for {
state <- current.get
newState = handleEvent(state, event)
_ <- eventRepository.insert(entityId, state.sequenceNr, event)
_ <- current.update(_ => newState)
} yield ()
}
// eventHandler: 설명을 위해 단순화한 예시 코드입니다.
private def handleEvent(state: State, event: Event): State =
(state, event) match {
case (_: State.Empty, _: Event.CommandReceived) => State.Initialized(???)
case (_: State.Empty, _: Event.FetchingChannelSucceeded) => State.ChannelSelected(???)
case (_: State.ChannelSelected, _: TgsSucceeded) => State.Paid(???)
...
}위 예시에선 설명을 위해 단순화한 부분이 많지만, Event Sourcing 구현의 핵심을 이루는 commandHandler 와 eventHandler 가 어떻게 구성되는지에 대해 충분히 감을 잡으셨을 것이라고 생각합니다.
Event Sourcing의 구현에 있어 더 디테일하게 신경 써야 할 부분들에 대해서는 심화편에서 좀 더 깊게 다루어보도록 하겠습니다!
Event Sourcing 도입에 따른 Challenge
저희가 Event Sourcing을 도입하게 된 것은 분명 해당 위에서 설명드린 여러 가지 장점을 누리기 위해서이지만, 반대로 해당 기술을 도입하면서 추가적으로 신경 써야 할 것들 또한 적지 않았습니다. 혹시 Event Sourcing의 도입을 고려하고 있지만 어떠한 챌린지가 있을지를 몰라 의사결정에 어려움을 겪고 계신 분들이 있다면, 그런 분들께 도움을 드리고자 제가 느낀 챌린지들을 공유하고자 합니다.
Challenge 1. Event 직렬화/역직렬화에 각별히 신경 써야 한다.
글의 윗부분에서 Event Sourcing의 특징에 대해 소개할 때, 해당 기술을 도입하게 되면 DB Schema에 의존하지 않는 자체적인 데이터 포맷 정의 및 직렬화/역직렬화 전략을 구성해야 한다고 말씀드렸는데요, 이는 장점과 단점이 공존하는 특징인 것 같습니다. DB Schema에 얽매이지 않고 자유롭게 데이터의 형식을 정의할 수 있게 되는 대신, 모든 이벤트를 DB에 저장할 수 있는 형태로 직렬화하고, 반대로 역직렬화하는 코드를 모두 수동으로 작성해야 합니다. 그리고 직렬화 포맷의 특성을 이해하고 이벤트가 하위 호환성을 유지할 수 있도록 많은 신경을 써주어야 합니다.
Challenge 2. DB를 직접 조작하기가 힘들다.
일반적으로 DB의 내용은 항상 어플리케이션을 통해서만 수정하는 것이 바람직하지만, 드물게는 개발자가 DB에 직접 접속해 데이터를 강제로 조작하는 경우도 있습니다. 이는 위험한 행동이긴 하지만 어쩔 수 없는 상황에서는 분명 유용할 수 있는 프랙티스입니다. 다만 이러한 접근은 DB에 담긴 데이터가 human-readable/human-updatable 할 때만 유용하며, Event Sourcing DB에는 직렬화된 데이터가 담기기 때문에 이 데이터를 사람이 수동으로 조작하는 것에는 한계가 있습니다. 이런 경우 강제 업데이트를 위한 별도의 기능을 어플리케이션에 개발해야 할 것입니다.
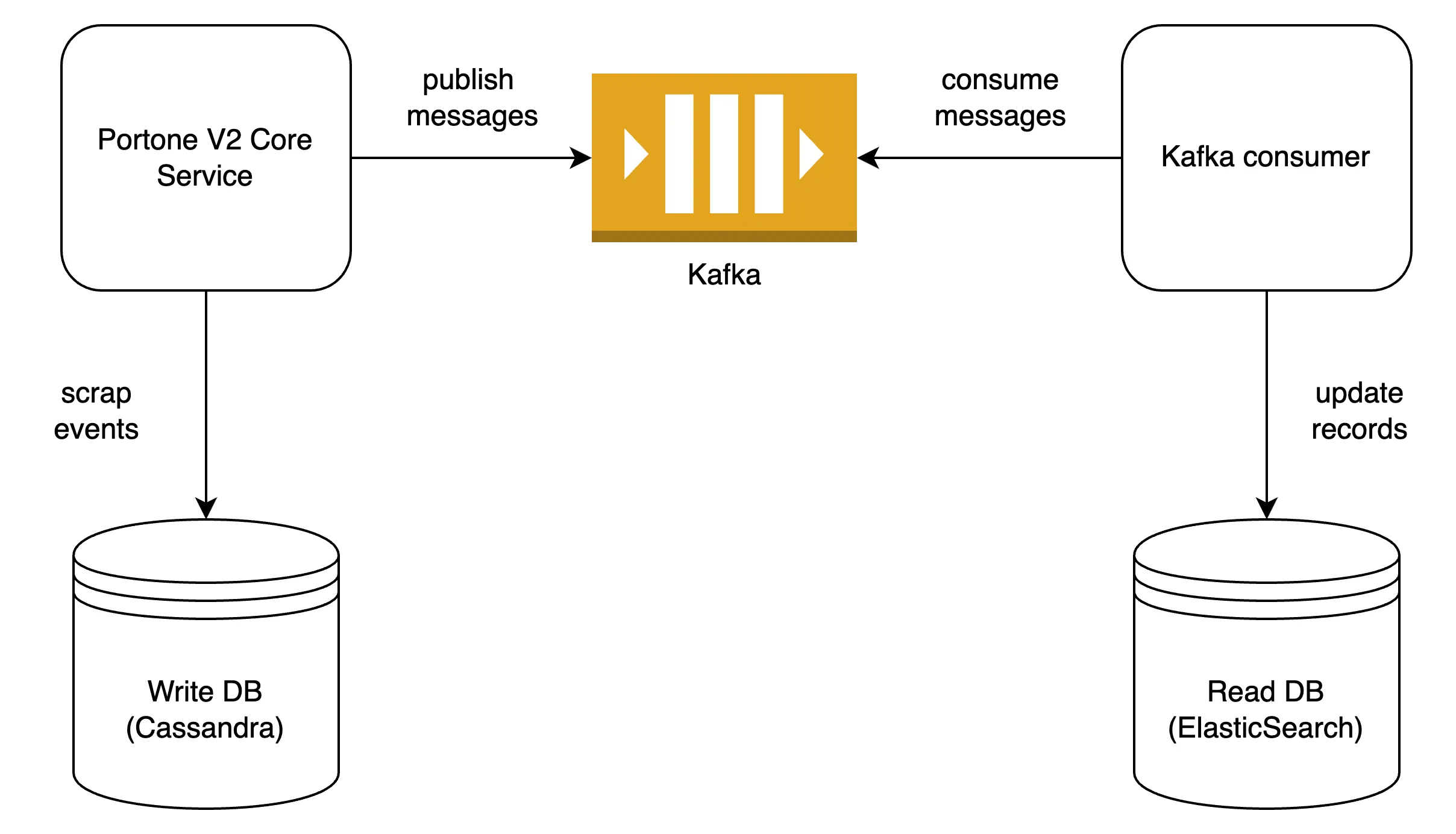
Challenge 3. 조회를 위한 별도의 모델이 필요하다.
사용자가 조회를 통해 얻고 싶은 것은 상태이지만, Event Sourcing DB의 record에는 개별 이벤트가 담겨있습니다. 따라서 Event Sourcing을 도입하게 되면 특정 조건으로 필터를 걸어 조건을 만족하는 엔티티를 한 번에 조회하는 등의 요구사항에 대응할 수 없습니다. Event Sourcing을 사용하면서 동시에 이러한 요구사항에 대응하기 위해서는 조회를 위한 별도의 모델이 필요합니다. 보통 Event Sourcing DB로부터 주기적으로 데이터를 전달받아 조회에 특화된 별도 DB에 데이터를 동기화하고 이 별도 DB를 조회 요구사항을 만족하는 식으로 접근하게 되는데, 이러한 접근 방식을 CQRS(Command-Query Responsibility Segregation) 패턴이라고 부릅니다. CQRS 패턴을 구현하기 위해서는 신뢰성 있는 데이터 동기화 아키텍처를 구성해야 하며, 이 아키텍처가 충분히 성숙해지기까지 꽤 많은 리소스를 들여야 할 것입니다.
정리
포트원 V2 시스템의 근간을 이루고 있는 Event Sourcing 기술의 개념과 도입 배경, 간단한 구현과 Challenge까지 개괄적인 내용을 함께 살펴보았습니다. Event Sourcing의 경우 굉장히 낯선 기술이고, 국내에서 해당 기술을 도입한 사례를 거의 찾아볼 수 없었기 때문에 저희도 실제로 이 기술을 도입하면서 많은 시행착오가 있었는데요, 많은 분들이 본 글을 읽고 Event Sourcing 기술이 가지는 특징과 장단점에 대해 더 깊게 이해하게 되셨기를 바래봅니다.
과감한 결정을 한 만큼 장기적으로 그 효과는 강력할 것이라고 생각합니다. Event Sourcing이라는 단단한 뿌리 위에서 폭발적으로 성장하는 포트원을 지켜봐 주세요!