Introduction
At PortOne, we use AWS DMS to capture changes from our service databases using Change Data Capture (CDC) and ingest them into our Data Lake. We store all our CDC data in AWS S3 and merge it with the BigQuery table every hour using Airflow as a scheduler. Our pipeline code, written in Python's Pandas library, merges incremental changes into the BigQuery table. We have multiple mart tables built on top of the raw tables in BigQuery.
Although this solution has worked well for us, we encountered several challenges along the way:
-
High Latency: at least an hour.
-
Manual Backfill: requires multiple steps to backfill data from the source database to the BigQuery table.
-
Missing Rows: There are instances of missing records if there are delays or complications with the writing process of AWS DMS.
-
High Maintenance: the solution requires multiple components to maintain, such as AWS DMS, Airflow, and a Kubernetes cluster to run all our pipelines.
Our approach involves utilizing GCP Datastream as our Change Data Capture (CDC) solution to address and overcome the aforementioned challenges.
About GCP Datastream
GCP Datastream is a managed CDC service provided by Google Cloud Platform (GCP) that enables real-time, automated, and reliable data replication from various sources to target destinations. It is a serverless and easy-to-use change data capture and replication service that directly ingests data from sources such as MySQL and Postgres into BigQuery.
It supports integrating various Google Cloud services, including BigQuery, Cloud Storage, and Pub/Sub.
Data Infrastructure Change
Before
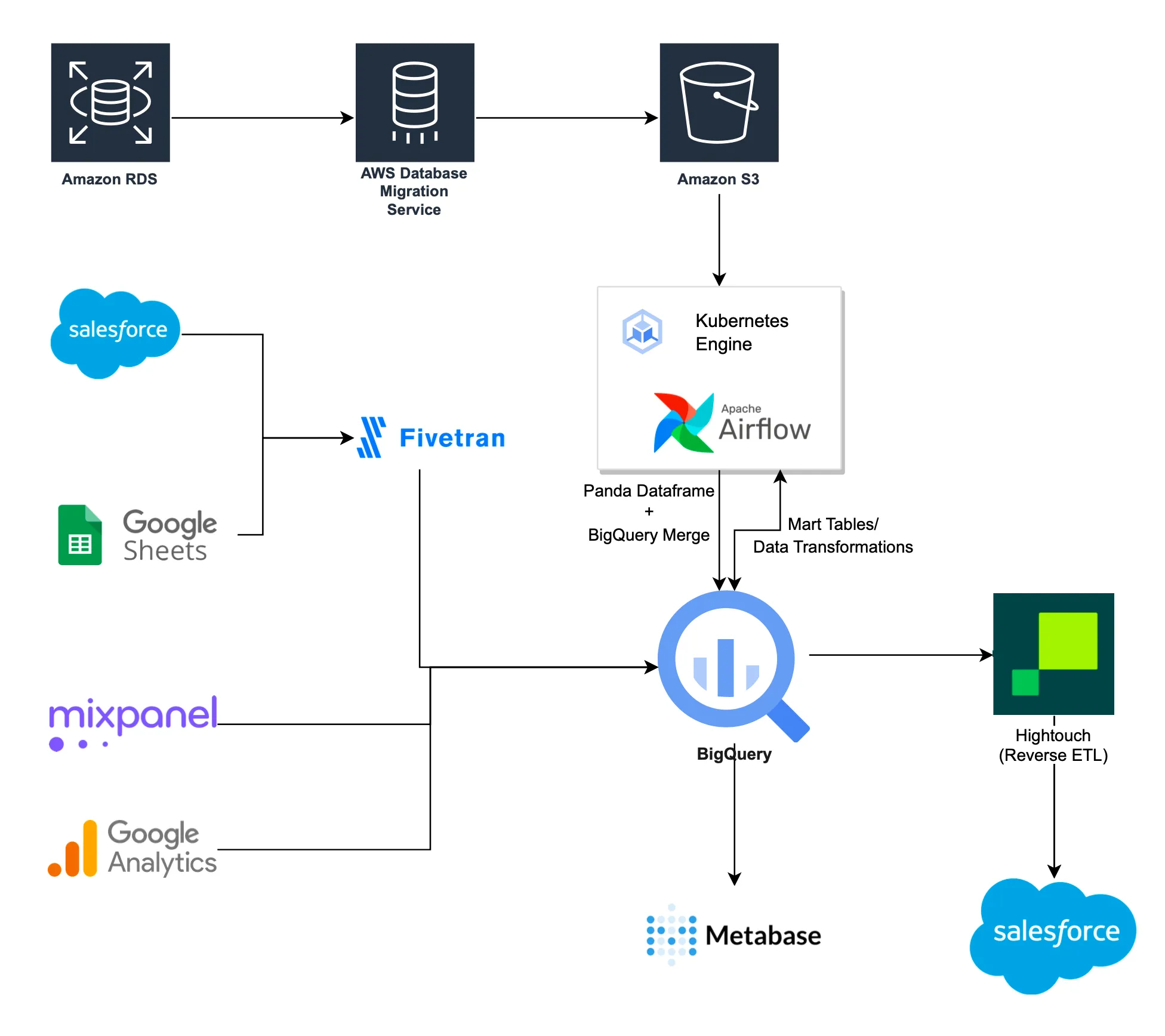
Here, we utilize AWS Database Migration Service(DMS) to capture changes in data from six to seven databases. The DMS consistently copies CDC data from RDS to Amazon S3 with hourly partitioning on S3. Next, Airflow initiates a DAG every hour to combine new CDC data from S3 to BigQuery. The underlying job, written in Pandas DataFrame, runs on Kubernetes and upserts the data in BigQuery.
After
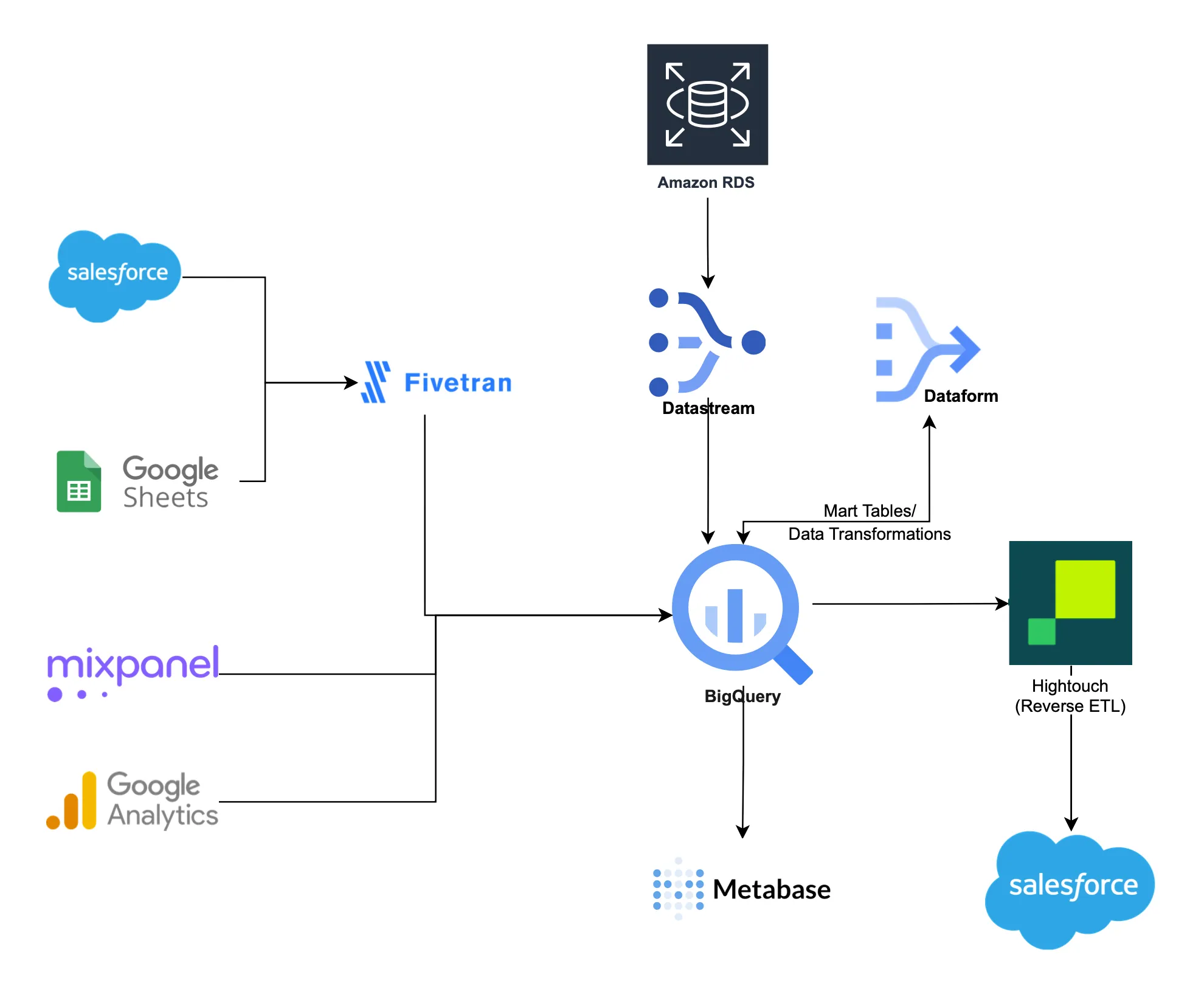
Here, we simplified the previous architecture by removing AWS DMS, AWS S3, and Data Pipelines run by Airflow. Instead, we utilize GCP Datastream, which directly connects to databases like PostgreSQL and MySQL, copies CDC data, and merges it into BigQuery. It provides the option to specify the staleness to balance BigQuery query performance and cost versus data freshness. Further details will be covered later in this blog.
Data Partitioning
Data partitioning allows for more efficient and scalable data processing by dividing data into smaller, manageable segments. This can lead to faster query performance, reduced costs, and improved data availability. It also allows for easier data management by providing the ability to load or delete data partitions selectively. Data partitioning plays a crucial role as we pay for the data scanned by the queries we run in BigQuery.
The main challenge with GCP Datastream is its lack of support for partitioning when writing data into BigQuery. As a result, all mart tables, which build incrementally every hour, must scan the full table ingested by Datastream, causing our BigQuery costs to skyrocket.
We manually created a partition for all large tables to mitigate this issue. Although this solution worked for us, we do not recommend it because it can affect your data ingestion. Please use it cautiously and consult GCP support if you encounter any issues.
Here are the steps we took to add a partition to the table ingested using Datastream. For example, we have a transaction table with over 100 million rows being ingested via Datastream and want to add a partition.
-
Pause the Datastream that ingests the transaction table.
-
Create a new transaction_v2 table using the same Data Definition Language (DDL) as the original transaction table but by appending the partition clause.
Find the DDL for the existing transaction table.
SELECT ddl FROM `<project-id>`.`region-<region-anme>`.INFORMATION_SCHEMA.TABLES WHERE table_name="transaction" and table_schema='<dataset name>'Use the DDL statement retrieve from above query and add your partition using
PARTITION BYclause.CREATE TABLE transaction_v2 ( id INT64, amount NUMERIC ) PARTITION BY DATE(updated_at) CLUSTER BY id; -
Insert data from the transaction into transaction_v2.
-
Drop the transaction table.
-
Create a new transaction table using the DDL of transaction_v2, which has the partition clause.
-
Insert data from transaction_v2 into the new transaction table.
-
Drop the transaction_v2 table.
-
Resume the Datastream.
Using updated_at as a partition column in the raw tables allows us to retrieve any new changes from the raw table without scanning the entire table for mart table updates.
Data Transformation
Key Features
We started using GCP Dataform for data transformation, enabling users to define, test, and deploy data models in a reproducible and modular manner. It helps data teams manage complex pipelines and maintain data quality efficiently.
-
SQL-based Data Transformations: Define and run SQL transformations on your data, and build complex pipelines with reusable scripts.
-
Dependency Management: Ensure transformations are executed in the right order and manage dependencies among them.
-
Version Control: Version control your data transformation code with Git, track changes, collaborate, and revert to previous versions if needed.
-
Testing and Validation: Write tests and validations for your data, and define rules and expectations to ensure quality and integrity.
-
Incremental Builds: Optimize the execution time of your data pipelines by processing only changed data since the last build.
-
Collaboration and Sharing: Share and reuse data transformation code with your team, create and manage projects, grant access, and promote code reuse across projects.
-
Scheduler Integration: Automate execution of your data pipelines at specified intervals with scheduling tools like Airflow or Google Cloud Scheduler.
-
Extensibility: Extend Dataform through plugins and custom JavaScript code, write custom logic, integrate with external systems, or implement advanced data processing tasks using JavaScript.
We haven't used GCP Dataform extensively at this time. We will share more information in the future after using it more.
Security
Datastream security
GCP Datastream is designed with security in mind and provides several features to ensure the security of data replication. Key features include encryption at rest and in transit, VPC service control, IAM roles and permissions, and audit logging.
PII column security
Our GCP Datastream-based pipeline uses two methods to handle Personally Identifiable Information (PII) columns. The first method completely blocks specific PII column(s) from being included in the Datastream. This ensures that Datastream does not ingest PII columns into BigQuery.
In some cases, our customer support or marketing team needs the PII of our customers, such as email, phone number, etc. In those cases, we ingest the PII column(s) into BigQuery and mask them using the dynamic data masking feature of BigQuery.
About Dynamic Data Masking
BigQuery provides dynamic data masking at the column level, enabling access to a column while obscuring its data for privileged user groups. Combining data masking with column-level access control allows you to configure access to column data at different levels based on user privileges. This simplifies data sharing, eliminates the need to modify existing queries, allows scalability when applying data access policies, and enables attribute-based access control.
Here are the benefits of using BigQuery for dynamic data masking at the column level:
-
Simplifies data sharing with larger groups by masking sensitive columns.
-
Existing queries automatically mask column data based on user roles, eliminating the need to exclude inaccessible columns.
-
Enables scalability of data access policies by writing a policy tag once and applying it to any number of columns.
-
Provides contextual data access based on data policy and associated principals through attribute-based access control.
Cost
Ingest required columns only
When using GCP Datastream, it is important to be mindful of the volume of data being ingested into BigQuery. Datastream charges based on the amount of data processed through it, so ensure to ingest only necessary tables and columns.
Use staleness settings
Data staleness in Datastream refers to the amount of time between when a change is made in the source database and when that change is captured and replicated in the target destination. Datastream provides an option to specify the staleness to balance BigQuery query performance and cost versus data freshness. By setting the staleness settings, merging costs can be reduced. However, setting too low of a staleness value can result in higher costs due to more frequent querying of the target destination.
To increase or decrease the staleness in the existing tables ingesting via Datastream.
ALTER TABLE <dataset-name>.<table_name>
SET OPTIONS (
max_staleness = INTERVAL 30 MINUTE
);Use BigQuery reservation for backfill
Setting reservation pricing before starting the backfill of large tables is important to reduce high backfill costs. In our case, we started the backfill of a large table without using BigQuery reservation, and the cost was 2 times higher than it would have been with reservation pricing.
The bottleneck of GCP Datastream
Lack of data partitioning
GCP Datastream is a powerful tool for real-time data replication, but it can still be improved in some areas. One major bottleneck is the lack of built-in partitioning. When a large table is ingested through Datastream, there should be an option to create a partition in the target table.
Lack of pre-transformation
Another challenge with GCP Datastream is the absence of pre-transformation. There is no option to transform the data before it is sent to the target system. This feature can help encrypt source columns, create derived columns, etc.
Full table scan while merging incremental changes
GCP Datastream scans the full table to apply a few incremental rows. This approach can be inefficient and expensive. To optimize the performance of GCP Datastream, developing a more efficient way of scanning the table and applying incremental rows is essential.
What’s Next?
We have made significant changes in our latest solution for ingesting real-time data from our source database to BigQuery. We have replaced AWS DMS with GCP Datastream. This has allowed us to take advantage of the unique features that GCP Datastream offers.
Additionally, we have implemented GCP Dataform for data modelling and mart tables. This has given us more flexibility and control over our data.
However, we have encountered a few challenges with GCP Datastream. It does not support pre-transformation, which is essential for our use case. To address this, we are considering using Dataflow for real-time pre-transformation. This would allow us to apply transformations to the data before it is ingested into BigQuery, giving us more control over the quality and consistency of our data. Overall, we believe that these changes have greatly improved the efficiency and effectiveness of our data ingestion process.

With over a decade of dedicated experience in Data Engineering, I specialize in crafting robust data solutions tailored to various sectors, including fintech, ride-hailing, and beyond. At PortOne, I am focused on building data infrastructure that empowers everyone to make data-informed decisions.